Scenario 1 - Catalog as Inventory
We know that information resource discovery takes place in a lot of different ways. It is possible (probable?) that the library catalog is not the primary information discovery resource for most users. In this scenario (which anyone can edit, hint, hint), the library catalog is mainly an inventory of owned, licensed, and otherwise available items managed by the library. Searching of the library catalog is for the most part a machine-to-machine activity. Users may or may not encounter a library catalog interface, because the catalog works in the background to provide access through other services. It looks basically like:
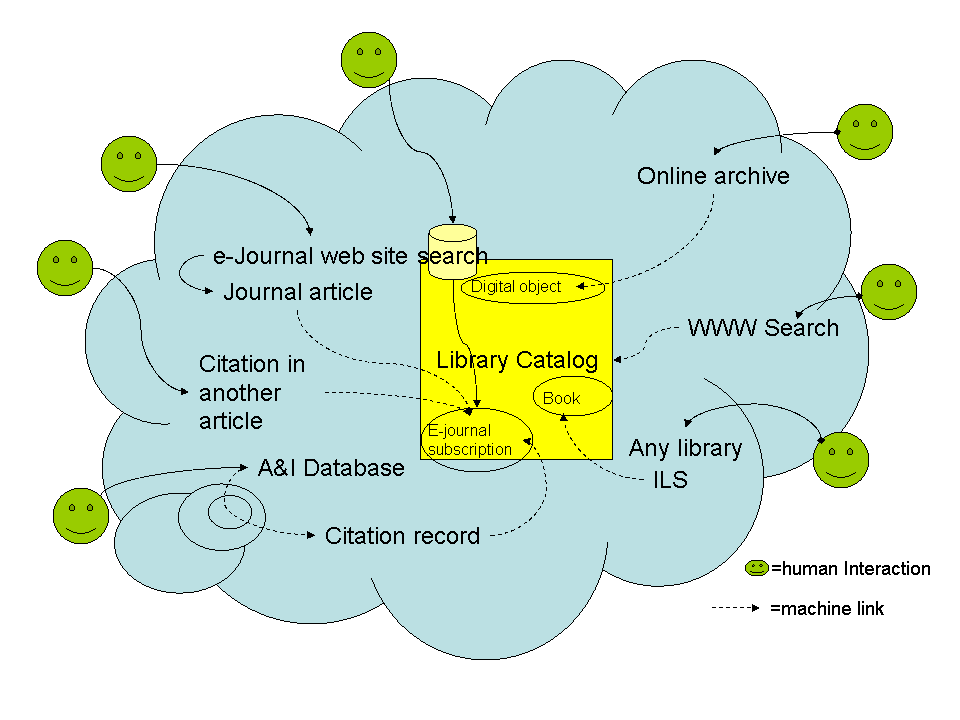
Although the catalog may need to have some direct search capabilities, the user interface is generally pushed out to other services that are closer to the user's actual workspace, such as courseware systems, web search engines, and actual documents. The effort in library systems development is in creating links to existing discovery services, or creating new discovery services that can be personalized, such as metasearch components.
Note: this seems to be similar to something I just found in Lorcan Dempsey's blog (9/16/06). He says: The need for an agreed service layer is growing. One important case is the developing interest in connecting a library discovery front end to an inventory management backend (see for example, Worldcat.org, the NCSU Catalog, Ex-Libris's Primo product, Libraries Australia, etc). This is required to determine availability etc. Of course, this is one example of mixing ILS functionality into another application.
One thing this does is that it takes some of the pressure off of library cataloging to provide rich topical discovery. What the library catalog does best is known item and related item (series, etc.) discovery. However, in this scenario accurate identification of resources across different systems is very important. The creation of machine-to-machine identification metadata could be separate from the identification provided by library catalog. Library cataloging, however, will be useful for displays and as downloadable citation information.
Comments (0)
You don't have permission to comment on this page.